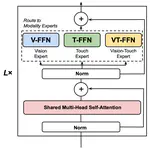
Anurag Renduchintala*, Adi Mahesh*, Zichen Zhang*, Zimo Si*, Shangjun Meng*, Samuel Fang*.
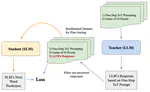
We introduce the One-Step Tree-of-Thoughts framework, a simplified prompting method that distills multi-step reasoning into a single structured prompt, and demonstrates how knowledge distillation can transfer this reasoning capability from Large Language Models to Small Language Models with much less parameters, enabling significant improvements reasoning performance, beating GPT-4o and GPT-4, as shown on the model's performance on Game of 24.