Zichen Zhang, Peihao Li, Yuan Cheng.
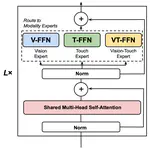
We introduce VTMo, a modular Vision-Touch Transformer encoder that unifies dual-encoder flexibility with fusion-encoder accuracy through a shared self-attention mechanism and modality-specific or cross-modal experts. VTMo supports image-only, touch-only, and vision-touch fusion tasks, offering versatility for speed or accuracy. Our method achieves competitive performance on the Image-to-Touch Retrieval task while reducing training time and computational complexity.